Dask¶
Dask enables parallel computing through task scheduling and blocked algorithms. This allows developers to write complex parallel algorithms and execute them in parallel either on a modern multi-core machine or on a distributed cluster.
On a single machine dask increases the scale of comfortable data from fits-in-memory to fits-on-disk by intelligently streaming data from disk and by leveraging all the cores of a modern CPU.
Users interact with dask either by making graphs directly or through the dask collections which provide larger-than-memory counterparts to existing popular libraries:
- dask.array = numpy + threading
- dask.bag = map, filter, toolz + multiprocessing
- dask.dataframe = pandas + threading
Dask primarily targets parallel computations that run on a single machine. It integrates nicely with the existing PyData ecosystem and is trivial to setup and use:
conda install dask
or
pip install dask
Operations on dask collections (array, bag, dataframe) produce task graphs that encode blocked algorithms. Task schedulers execute these task graphs in parallel in a variety of contexts.
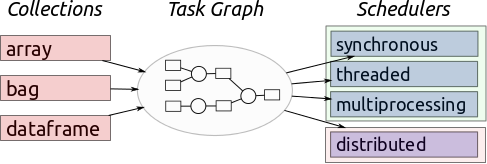
Collections:
Dask collections are the main interaction point for users. They look like NumPy and pandas but generate dask graphs internally. If you are a dask user then you should start here.
Graphs:
Dask graphs encode algorithms in a simple format involving Python dicts, tuples, and functions. This graph format can be used in isolation from the dask collections. If you are a developer then you should start here.
Scheduling:
Schedulers execute task graphs. After a collection produces a graph we execute this graph in parallel, either using all of the cores on a single workstation or using a distributed cluster.
Other
Contact
- For user questions please tag StackOverflow questions with the #dask tag.
- For bug reports and feature requests please use the GitHub issue tracker
- For community discussion please use blaze-dev@continuum.io
Dask is part of the Blaze project supported by Continuum Analytics