Optimization¶
Small optimizations performed on the dask graph before calling the scheduler can significantly improve performance in different contexts. The dask.optimize module contains several functions to transform graphs in a variety of useful ways. In most cases, users won’t need to interact with these functions directly - specialized subsets of these transforms are done automatically in the dask collections (dask.array, dask.bag, and dask.dataframe). However, users working with custom graphs or computations may find that applying these methods results in substantial speedups.
In general, there are two goals when doing graph optimizations
- Simplify computation
- Improve parallelism
Simplifying computation can be done on a graph level by removing unnecessary tasks (cull), or on a task level by replacing expensive operations with cheaper ones (RewriteRule). Parallelism can be improved by reducing inter-task communication, whether by fusing many tasks into one (fuse), or by inlining cheap operations (inline, inline_functions).
Below, we show an example walking through the use of some of these to optimize a task graph.
Example¶
Suppose you had a custom dask graph for doing a word counting task.
>>> from __future__ import print_function
>>> def print_and_return(string):
print(string)
return string
>>> format_str = 'word list has {0} occurrences of {1}, out of {2} words'
>>> dsk = {'words': 'apple orange apple pear orange pear pear',
'nwords': (len, (str.split, 'words')),
'val1': 'orange',
'val2': 'apple',
'val3': 'pear',
'count1': (str.count, 'words', 'val1'),
'count2': (str.count, 'words', 'val2'),
'count3': (str.count, 'words', 'val3'),
'out1': (format_str.format, 'count1', 'val1', 'nwords'),
'out2': (format_str.format, 'count2', 'val2', 'nwords'),
'out3': (format_str.format, 'count3', 'val3', 'nwords'),
'print1': (print_and_return, 'out1'),
'print2': (print_and_return, 'out2'),
'print3': (print_and_return, 'out3')}
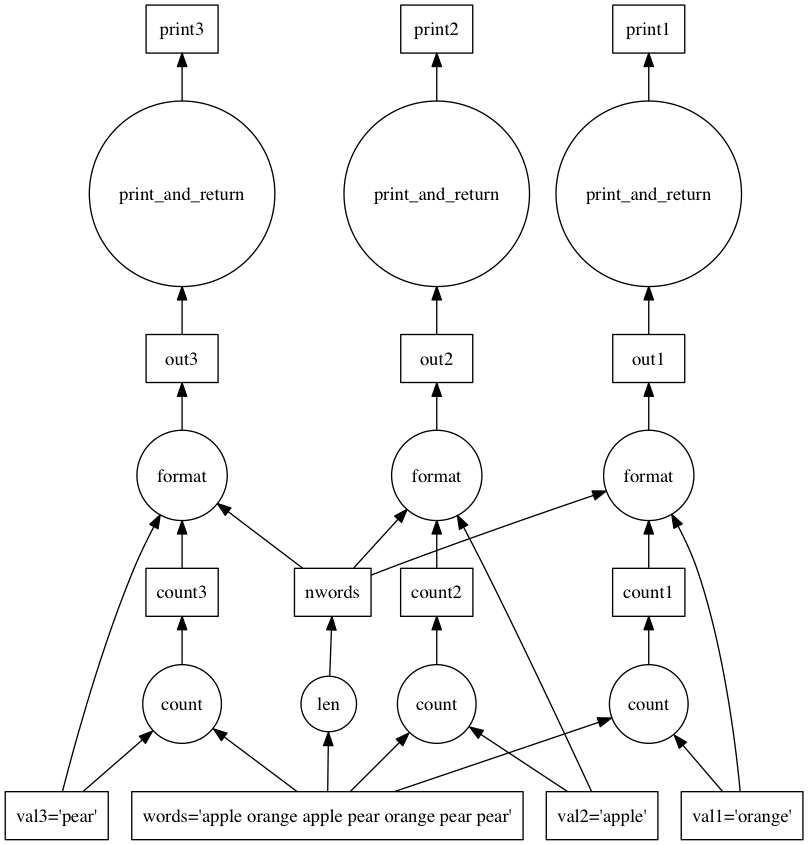
Here we’re counting the occurence of the words 'orange, 'apple', and 'pear' in the list of words, formatting an output string reporting the results, printing the output, then returning the output string.
To perform the computation, we pass the dask and the desired output keys to a scheduler get function.
>>> from dask.multiprocessing import get
>>> results = get(dsk, ['print1', 'print2'])
word list has 3 occurrences of pear, out of 7 words
word list has 2 occurrences of apple, out of 7 words
word list has 2 occurrences of orange, out of 7 words
>>> results
('word list has 2 occurrences of orange, out of 7 words',
'word list has 2 occurrences of apple, out of 7 words')
As can be seen above, the schedulers computed the whole graph before returning just a few of the outputs. This is because the schedulers will always compute all tasks, even if we only requested a few of the output keys. Before we pass the dask to get, we need to remove the unnecessary tasks from the graph. To do this, we can use the cull function.
>>> from dask.optimize import cull
>>> dsk1 = cull(dsk, ['print1', 'print2'])
>>> results = get(dsk1, ['print1', 'print2'])
word list has 2 occurrences of apple, out of 7 words
word list has 2 occurrences of orange, out of 7 words
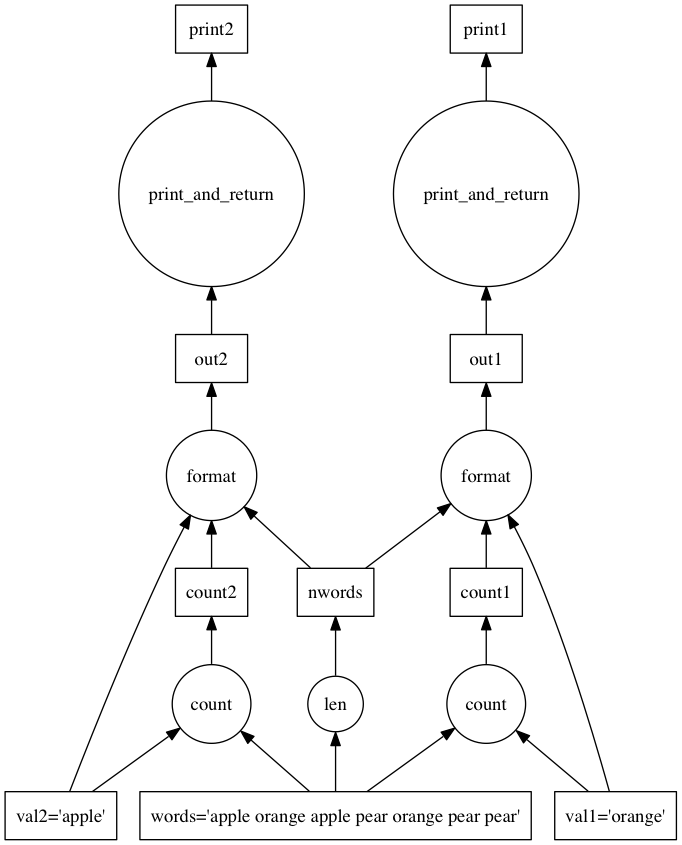
Looking at the task graph above, there are multiple accesses to constants such as 'val1' or 'val2' in the dask. These can be inlined into the tasks to improve efficiency using the inline function.
>>> from dask.optimize import inline
>>> dsk2 = inline(dsk1)
>>> results = get(dsk2, ['print1', 'print2'])
word list has 2 occurrences of apple, out of 7 words
word list has 2 occurrences of orange, out of 7 words
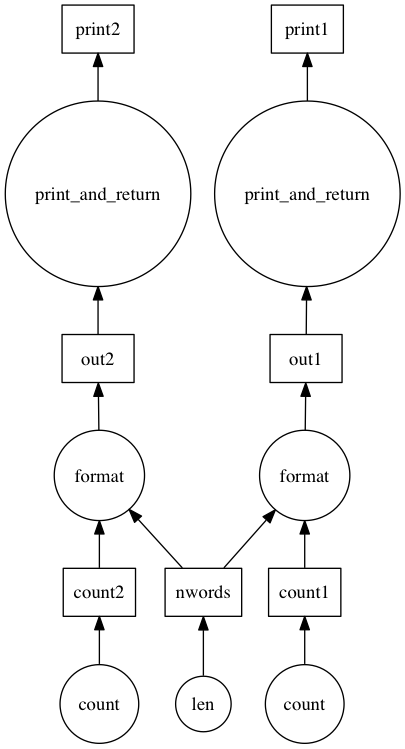
Now we have two sets of almost linear task chains. The only link between them is the word counting function. For cheap operations like this, the serialization cost may be larger than the actual computation, so it may be faster to do the computation more than once, rather than passing the results to all nodes. To perform this function inlining, the inline_functions function can be used.
>>> from dask.optimize import inline_functions
>>> dsk3 = inline_functions(dsk2, [len, str.split])
>>> results = get(dsk3, ['print1', 'print2'])
word list has 2 occurrences of apple, out of 7 words
word list has 2 occurrences of orange, out of 7 words
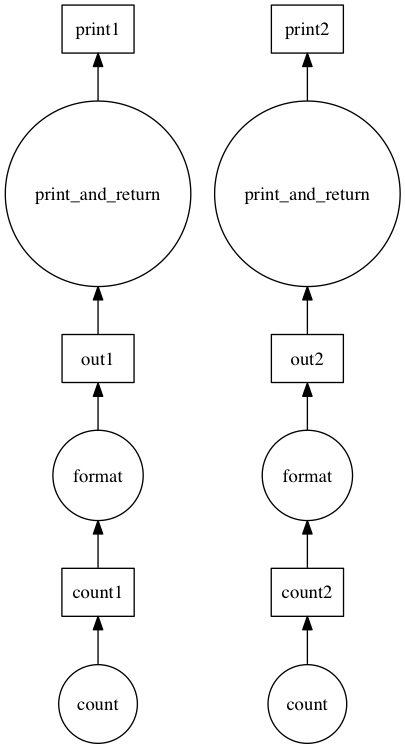
Now we have a set of purely linear tasks. We’d like to have the scheduler run all of these on the same worker to reduce data serialization between workers. One option is just to merge these linear chains into one big task using the fuse function.
>>> from dask.optimize import fuse
>>> dsk4 = fuse(dsk3)
>>> results = get(dsk4, ['print1', 'print2'])
word list has 2 occurrences of apple, out of 7 words
word list has 2 occurrences of orange, out of 7 words
Putting it all together:
>>> def optimize_and_get(dsk, keys):
dsk1 = cull(dsk, keys)
dsk2 = inline(dsk1)
dsk3 = inline_functions(dsk2, [len, str.split])
dsk4 = fuse(dsk2)
return get(dsk4, keys)
>>> optimize_and_get(dsk, ['print1', 'print2'])
word list has 2 occurrences of apple, out of 7 words
word list has 2 occurrences of orange, out of 7 words
In summary, the above operations:
- Removed tasks unncessary for the desired output using cull
- Inlined constants using inline
- Inlined cheap computations using inline_functions, improving parallelism
- Fused linear tasks together to ensure they run on the same worker, using fuse
These are just a few of the optimizations provided in dask.optimize, for more information see the api below. As stated previously, these optimizations are already performed automatically in the dask collections. Users not working with custom graphs or computations should have little reason to directly interact with them.
Rewrite Rules¶
For context based optimizations, dask.rewrite provides functionality for pattern matching and term rewriting. This is useful for replacing expensive computations with equivalent, cheaper computations. For example, dask.array uses the rewrite functionality to replace series of array slicing operations with a more efficient single slice.
The interface to the rewrite system consists of two classes:
RewriteRule(lhs, rhs, vars)
Given a left-hand-side (lhs), a right-hand-side (rhs), and a set of variables (vars), a rewrite rule declaratively encodes the following operation:
lhs -> rhs if task matches lhs over variables
RuleSet(*rules)
A collection of rewrite rules. The design of RuleSet class allows for efficient “many-to-one” pattern matching, meaning that there is minimal overhead for rewriting with multiple rules in a rule set.
Example¶
Here we create two rewrite rules expressing the following mathematical transformations:
- a + a -> 2*a
- a * a -> a**2
where 'a' is a variable.
>>> from dask.rewrite import RewriteRule, RuleSet
>>> from operator import add, mul, pow
>>> variables = ('a',)
>>> rule1 = RewriteRule((add, 'a', 'a'), (mul, 'a', 2), variables)
>>> rule2 = RewriteRule((mul, 'a', 'a'), (pow, 'a', 2), variables)
>>> rs = RuleSet(rule1, rule2)
The RewriteRule objects describe the desired transformations in a declarative way, and the RuleSet builds an efficient automata for applying that transformation. Rewriting can then be done using the rewrite method.
>>> rs.rewrite((add, 5, 5))
(mul, 1, 2)
>>> rs.rewrite((mul, 5, 5))
(pow, 5, 2)
>>> rs.rewrite((mul, (add, 3, 3), (add, 3, 3)))
(pow, (mul, 3, 2), 2)
The whole task is traversed by default. If you only want to apply a transform to the top-level of the task, you can pass in strategy='top_level'.
# Transforms whole task
>>> rs.rewrite((sum, [(add, 3, 3), (mul, 3, 3)]))
(sum, [(mul, 3, 2), (pow, 3, 2)])
# Only applies to top level, no transform occurs
>>> rs.rewrite((sum, [(add, 3, 3), (mul, 3, 3)]), strategy='top_level')
(sum, [(add, 3, 3), (mul, 3, 3)])
The rewriting system provides a powerful abstraction for transforming computations at a task level, but for many users directly interacting with these transformations will be unnecessary.
API¶
Top level optimizations
| cull(dsk, keys) | Return new dask with only the tasks required to calculate keys. |
| fuse(dsk[, keys]) | Return new dask with linear sequence of tasks fused together. |
| inline(dsk[, keys, inline_constants]) | Return new dask with the given keys inlined with their values. |
| inline_functions(dsk[, fast_functions, ...]) | Inline cheap functions into larger operations |
Utility functions
| dealias(dsk) | Remove aliases from dask |
| dependency_dict(dsk) | Create a dict matching ordered dependencies to keys. |
| equivalent(term1, term2[, subs]) | Determine if two terms are equivalent, modulo variable substitution. |
| functions_of(task) | Set of functions contained within nested task |
| merge_sync(dsk1, dsk2) | Merge two dasks together, combining equivalent tasks. |
| sync_keys(dsk1, dsk2) | Return a dict matching keys in dsk2 to equivalent keys in dsk1. |
Rewrite Rules
| RewriteRule(lhs, rhs[, vars]) | A rewrite rule. |
| RuleSet(*rules) | A set of rewrite rules. |
Definitions¶
- dask.optimize.cull(dsk, keys)¶
Return new dask with only the tasks required to calculate keys.
In other words, remove unnecessary tasks from dask. keys may be a single key or list of keys.
Examples
>>> d = {'x': 1, 'y': (inc, 'x'), 'out': (add, 'x', 10)} >>> cull(d, 'out') {'x': 1, 'out': (add, 'x', 10)}
- dask.optimize.fuse(dsk, keys=None)¶
Return new dask with linear sequence of tasks fused together.
If specified, the keys in keys keyword argument are not fused.
This may be used as an optimization step.
Examples
>>> d = {'a': 1, 'b': (inc, 'a'), 'c': (inc, 'b')} >>> fuse(d) {'c': (inc, (inc, 1))} >>> fuse(d, keys=['b']) {'b': (inc, 1), 'c': (inc, 'b')}
- dask.optimize.inline(dsk, keys=None, inline_constants=True)¶
Return new dask with the given keys inlined with their values.
Inlines all constants if inline_constants keyword is True.
Examples
>>> d = {'x': 1, 'y': (inc, 'x'), 'z': (add, 'x', 'y')} >>> inline(d) {'y': (inc, 1), 'z': (add, 1, 'y')}
>>> inline(d, keys='y') {'z': (add, 1, (inc, 1))}
>>> inline(d, keys='y', inline_constants=False) {'x': 1, 'z': (add, 'x', (inc, 'x'))}
- dask.optimize.inline_functions(dsk, fast_functions=None, inline_constants=False)¶
Inline cheap functions into larger operations
Examples
>>> dsk = {'out': (add, 'i', 'd'), ... 'i': (inc, 'x'), ... 'd': (double, 'y'), ... 'x': 1, 'y': 1} >>> inline_functions(dsk, [inc]) {'out': (add, (inc, 'x'), 'd'), 'd': (double, 'y'), 'x': 1, 'y': 1}
- dask.optimize.dealias(dsk)¶
Remove aliases from dask
Removes and renames aliases using inline. Keeps aliases at the top of the DAG to ensure entry points stay the same.
Aliases are not expected by schedulers. It’s unclear that this is a legal state.
Examples
>>> dsk = {'a': (range, 5), ... 'b': 'a', ... 'c': 'b', ... 'd': (sum, 'c'), ... 'e': 'd', ... 'f': (inc, 'd')}
>>> dealias(dsk) {'a': (range, 5), 'd': (sum, 'a'), 'e': (identity, 'd'), 'f': (inc, 'd')}
- dask.optimize.dependency_dict(dsk)¶
Create a dict matching ordered dependencies to keys.
Examples
>>> from operator import add >>> dsk = {'a': 1, 'b': 2, 'c': (add, 'a', 'a'), 'd': (add, 'b', 'a')} >>> dependency_dict(dsk) {(): ['a', 'b'], ('a', 'a'): ['c'], ('b', 'a'): ['d']}
- dask.optimize.equivalent(term1, term2, subs=None)¶
Determine if two terms are equivalent, modulo variable substitution.
Equivalent to applying substitutions in subs to term2, then checking if term1 == term2.
If a subterm doesn’t support comparison (i.e. term1 == term2 errors), returns False.
Parameters: term1, term2 : terms
subs : dict, optional
Mapping of substitutions from term2 to term1
Examples
>>> from operator import add >>> term1 = (add, 'a', 'b') >>> term2 = (add, 'x', 'y') >>> subs = {'x': 'a', 'y': 'b'} >>> equivalent(term1, term2, subs) True >>> subs = {'x': 'a'} >>> equivalent(term1, term2, subs) False
- dask.optimize.functions_of(task)¶
Set of functions contained within nested task
Examples
>>> task = (add, (mul, 1, 2), (inc, 3)) >>> functions_of(task) set([add, mul, inc])
- dask.optimize.merge_sync(dsk1, dsk2)¶
Merge two dasks together, combining equivalent tasks.
If a task in dsk2 exists in dsk1, the task and key from dsk1 is used. If a task in dsk2 has the same key as a task in dsk1 (and they aren’t equivalent tasks), then a new key is created for the task in dsk2. This prevents name conflicts.
Parameters: dsk1, dsk2 : dict
Variable names in dsk2 are replaced with equivalent ones in dsk1 before merging.
Returns: new_dsk : dict
The merged dask.
key_map : dict
A mapping between the keys from dsk2 to their new names in new_dsk.
Examples
>>> from operator import add, mul >>> dsk1 = {'a': 1, 'b': (add, 'a', 10), 'c': (mul, 'b', 5)} >>> dsk2 = {'x': 1, 'y': (add, 'x', 10), 'z': (mul, 'y', 2)} >>> new_dsk, key_map = merge_sync(dsk1, dsk2) >>> new_dsk {'a': 1, 'b': (add, 'a', 10), 'c': (mul, 'b', 5), 'z': (mul, 'b', 2)} >>> key_map {'x': 'a', 'y': 'b', 'z': 'z'}
Conflicting names are replaced with auto-generated names upon merging.
>>> dsk1 = {'a': 1, 'res': (add, 'a', 1)} >>> dsk2 = {'x': 1, 'res': (add, 'x', 2)} >>> new_dsk, key_map = merge_sync(dsk1, dsk2) >>> new_dsk {'a': 1, 'res': (add, 'a', 1), 'merge_1': (add, 'a', 2)} >>> key_map {'x': 'a', 'res': 'merge_1'}
- dask.optimize.sync_keys(dsk1, dsk2)¶
Return a dict matching keys in dsk2 to equivalent keys in dsk1.
Parameters: dsk1, dsk2 : dict Examples
>>> from operator import add, mul >>> dsk1 = {'a': 1, 'b': (add, 'a', 10), 'c': (mul, 'b', 5)} >>> dsk2 = {'x': 1, 'y': (add, 'x', 10), 'z': (mul, 'y', 2)} >>> sync_keys(dsk1, dsk2) {'x': 'a', 'y': 'b'}
- dask.rewrite.RewriteRule(lhs, rhs, vars=())¶
A rewrite rule.
Expresses lhs -> rhs, for variables vars.
Parameters: lhs : task
The left-hand-side of the rewrite rule.
rhs : task or function
The right-hand-side of the rewrite rule. If it’s a task, variables in rhs will be replaced by terms in the subject that match the variables in lhs. If it’s a function, the function will be called with a dict of such matches.
vars: tuple, optional
Tuple of variables found in the lhs. Variables can be represented as any hashable object; a good convention is to use strings. If there are no variables, this can be omitted.
- dask.rewrite.RuleSet(*rules)¶
A set of rewrite rules.
Forms a structure for fast rewriting over a set of rewrite rules. This allows for syntactic matching of terms to patterns for many patterns at the same time.
Examples
>>> def f(*args): pass >>> def g(*args): pass >>> def h(*args): pass >>> from operator import add
>>> rs = RuleSet( # Make RuleSet with two Rules ... RewriteRule((add, 'x', 0), 'x', ('x',)), ... RewriteRule((f, (g, 'x'), 'y'), ... (h, 'x', 'y'), ... ('x', 'y')))
>>> rs.rewrite((add, 2, 0)) # Apply ruleset to single task 2
>>> rs.rewrite((f, (g, 'a', 3))) (h, 'a', 3)
>>> dsk = {'a': (add, 2, 0), # Apply ruleset to full dask graph ... 'b': (f, (g, 'a', 3))}
>>> from toolz import valmap >>> valmap(rs.rewrite, dsk) {'a': 2, 'b': (h, 'a', 3)}
Attributes
rules (list) A list of RewriteRule`s included in the `RuleSet.