Custom Graphs¶
There may be times that you want to do parallel computing, but your application
doesn’t fit neatly into something like dask.array or dask.bag. In these
cases, you can interact directly with the dask schedulers. These schedulers
operate well as standalone modules.
This separation provides a release valve for complex situations and allows advanced projects additional opportunities for parallel execution, even if those projects have an internal representation for their computations. As dask schedulers improve or expand to distributed memory, code written to use dask schedulers will advance as well.
Example¶
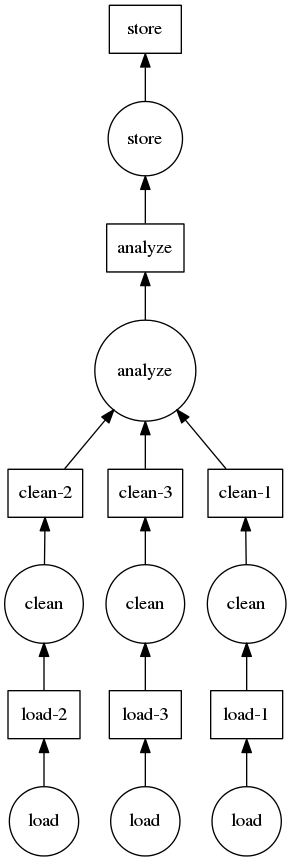
As discussed in the motivation and specification sections, the schedulers take a task graph which is a dict of tuples of functions, and a list of desired keys from that graph.
Here is a mocked out example building a graph for a traditional clean and analyze pipeline:
def load(filename):
...
def clean(data):
...
def analyze(sequence_of_data):
...
def store(result):
with open(..., 'w') as f:
f.write(result)
dsk = {'load-1': (load, 'myfile.a.data'),
'load-2': (load, 'myfile.b.data'),
'load-3': (load, 'myfile.c.data'),
'clean-1': (clean, 'load-1'),
'clean-2': (clean, 'load-2'),
'clean-3': (clean, 'load-3'),
'analyze': (analyze, ['clean-%d' % i for i in [1, 2, 3]]),
'store': (store, 'analyze')}
from dask.multiprocessing import get
get(dsk, 'store') # executes in parallel