Dask¶
Dask is a flexible parallel computing library for analytics. Dask emphasizes the following virtues:
- Familiar: Provides parallelized NumPy array and Pandas DataFrame objects
- Native: Enables distributed computing in Pure Python with access to the PyData stack.
- Fast: Operates with low overhead, low latency, and minimal serialization necessary for fast numerical algorithms
- Flexible: Supports complex and messy workloads
- Scales up: Runs resiliently on clusters with 100s of nodes
- Scales down: Trivial to set up and run on a laptop in a single process
- Responsive: Designed with interactive computing in mind it provides rapid feedback and diagnostics to aid humans
Familiar user interface¶
Dask DataFrame mimics Pandas
import pandas as pd import dask.dataframe as dd
df = pd.read_csv('2015-01-01.csv') df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean() df.groupby(df.user_id).value.mean().compute()
Dask Array mimics NumPy
import numpy as np import dask.array as da
f = h5py.File('myfile.hdf5') f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data']) x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
x - x.mean(axis=1) x - x.mean(axis=1).compute()
Dask Bag mimics iterators, Toolz, PySpark
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()
Dask Delayed mimics for loops and wraps custom code
from dask import delayed
L = []
for fn in filenames: # Use for loops to build up computation
data = delayed(load)(fn) # Delay execution of function
L.append(delayed(process)(data)) # Build connections between variables
result = delayed(summarize)(L)
result.compute()
Scales from laptops to clusters¶
Dask is convenient on a laptop. It installs trivially with
conda or pip and extends the size of convenient datasets from “fits in
memory” to “fits on disk”.
Dask can scale to a cluster of 100s of machines. It is resilient, elastic, data local, and low latency. For more information see documentation on the distributed scheduler.
This ease of transition between single-machine to moderate cluster enables users both to start simple and to grow when necessary.
Complex Algorithms¶
Dask represents parallel computations with task graphs. These
directed acyclic graphs may have arbitrary structure, which enables both
developers and users the freedom to build sophisticated algorithms and to
handle messy situations not easily managed by the map/filter/groupby
paradigm common in most data engineering frameworks.
We originally needed this complexity to build complex algorithms for n-dimensional arrays but have found it to be equally valuable when dealing with messy situations in everyday problems.
Index¶
Getting Started
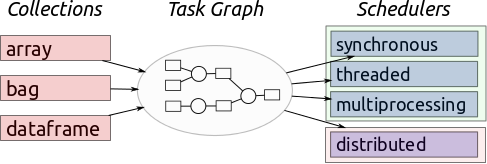
Collections
Dask collections are the main interaction point for users. They look like NumPy and pandas but generate dask graphs internally. If you are a dask user then you should start here.
Graphs
Dask graphs encode algorithms in a simple format involving Python dicts, tuples, and functions. This graph format can be used in isolation from the dask collections. Working directly with dask graphs is an excellent way to implement and test new algorithms in fields such as linear algebra, optimization, and machine learning. If you are a developer, you should start here.
Scheduling
Schedulers execute task graphs. Dask currently has two main schedulers, one for single machine processing using threads or processes, and one for distributed memory clusters.
- Scheduler Overview
- Single machine scheduler
- Distributed scheduler (separate webpage)
- Scheduling in Depth
Inspecting and Diagnosing Graphs
Parallel code can be tricky to debug and profile. Dask provides a few tools to help make debugging and profiling graph execution easier.
Help & reference
Contact
- For user questions please tag StackOverflow questions with the #dask tag.
- For bug reports and feature requests please use the GitHub issue tracker
- For community discussion please use blaze-dev@continuum.io
- For chat, see gitter chat room
Dask is part of the Blaze project supported and offered by Continuum Analytics and contributors under a 3-clause BSD license.